

音声生成プラットフォーム「にじボイス」。そのAPIがリリースされました。
・APIなのでPC環境に依存しない(低スペックPCでも音声合成できる)
・新規アカウントに5,000文字無料でついてくる
というわけでAITuberに使ってみた。
Pythonを使って生成していく。
まずはにじボイスのAPIキーを取得。
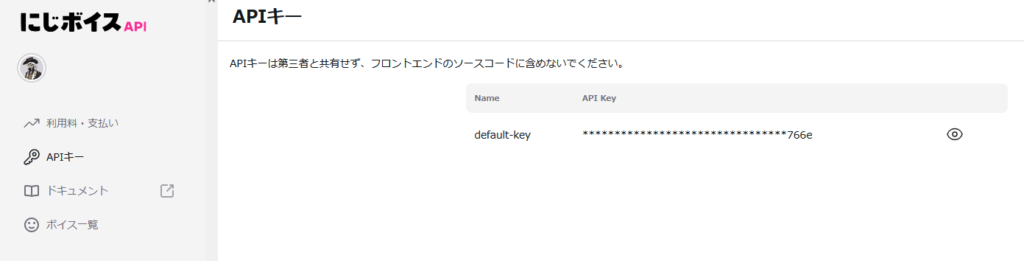
Googleアカウントでログインし、APIキーのページを開く。
目のマークを押すと表示されるけど、絶対に他人に見せちゃいけないよ。
次にボイス一覧からキャラ(声)を探す。
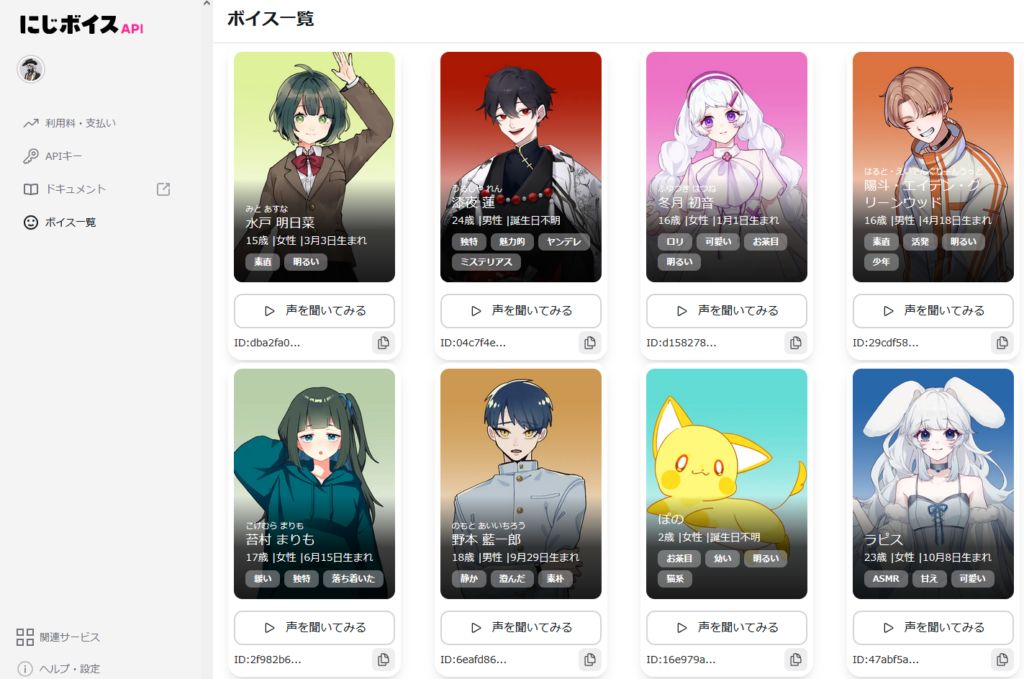
右下のコピーマークをクリックするとコピーできるよ。
次はコードを書いていく。
私はAITuber本の影響をもろに受けているので以下のようにした。
nijivoice_adapter.py
import os
import requests
import sounddevice as sd
import soundfile as sf
from datetime import datetime
from dotenv import load_dotenv
class nijivoiceAdapter:
def __init__(self) -> None:
load_dotenv()
self.api = os.environ.get('NIJIVOICE_API')
self.id = os.environ.get('NIJIVOICE_ID')
self.url = f"https://api.nijivoice.com/api/platform/v1/voice-actors/{self.id}/generate-voice"
self.path = "C:/Users/nekuron/Desktop/mp3/"
def play_voice(self, text):
payload = {
"format": "mp3",
"speed": "1.0",
"script": f"{text}"
}
headers = {
"accept": "application/json",
"x-api-key": f"{self.api}",
"content-type": "application/json"
}
try:
response = requests.post(self.url, json=payload, headers=headers)
response.raise_for_status() # HTTPエラーの確認
except requests.exceptions.RequestException as e:
print(f"Error occurred during POST request: {e}")
return
try:
response_data = response.json()
audio_file_url = response_data["generatedVoice"]["audioFileDownloadUrl"]
except (KeyError, ValueError) as e:
print(f"Error parsing response JSON: {e}")
return
try:
audio_response = requests.get(audio_file_url)
name = self.path + self.generate_filename()
f = open(name,"wb")
f.write(audio_response.content)
f.close()
except requests.exceptions.RequestException as e:
print(f"Error occurred during GET request for audio file: {e}")
return
try:
self.play_audio(name)
except Exception as e:
print(f"Error processing or playing audio: {e}")
# 音声ファイルを読み込んで再生
def play_audio(self, file_path):
try:
# 音声ファイルを読み込む
data, samplerate = sf.read(file_path)
# 再生
sd.play(data, samplerate)
# 再生終了まで待機
sd.wait()
print("再生が完了しました!")
except Exception as e:
print(f"エラーが発生しました: {e}")
def generate_filename(self):
# 現在の日時を取得
now = datetime.now()
# フォーマットを指定して文字列に変換
filename = now.strftime("%Y%m%d%H%M%S") + ".mp3"
return filename
if __name__ == '__main__':
adapter = nijivoiceAdapter()
adapter.play_voice("てすと")まずAPIなどは環境変数として.envに記載している。
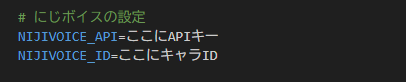
公開したらダメだぞ?絶対だぞ?
さてほかの人の記事にはない書き方をしている。
というのも謎に詰まって、試行錯誤、最終的にいったんmp3ファイルを保存することになったのだ。
・・・( ˘ω˘ )ほかの人は直接再生しているね
このコードで試す人がいるなら「self.path = "C:/Users/nekuron/Desktop/mp3/"」の部分のパスを自分の環境に合わせて変えてほしい。
ちなみにこれはデスクトップにmp3フォルダを作ってます。
ファイル名がかぶらないように時間でファイル名を決めている。
コードだと「generate_filename」関数だ。
使いたいときは「nijivoiceAdapter」の「play_voice」にテキストを渡すだけでいい。
この「nijivoiceAdapter」を組み込んだAITuberでテスト配信してみた。
この動画はN100という非力なマシンで配信できるかのテストだったのだが、需要あったのかな・・・
ちなみに話していた時間は5分未満だけど、1000クレジット使いました。
ちゃんとした雑談配信するなら課金必須だね。
